Notwendigkeit der Skalenumwandlung der Zielvariablen [Maschinelles Lernen]
Es wird oft argumentiert, dass die Feature-Konvertierung beim maschinellen Lernen und beim Deep Learning wichtig ist.Zum Beispiel die folgenden Bücher.
Andererseits gab es nicht viele Informationen über die Zielvariable.Daher werde ich das Ergebnis der Untersuchung zusammenfassen, ob die Zielvariable in der Regressionsaufgabe konvertiert werden soll.
Die Zielvariable muss skaliert werden
Natürlich besteht in einigen Fällen ein Bedarf.
Notwendige Szene
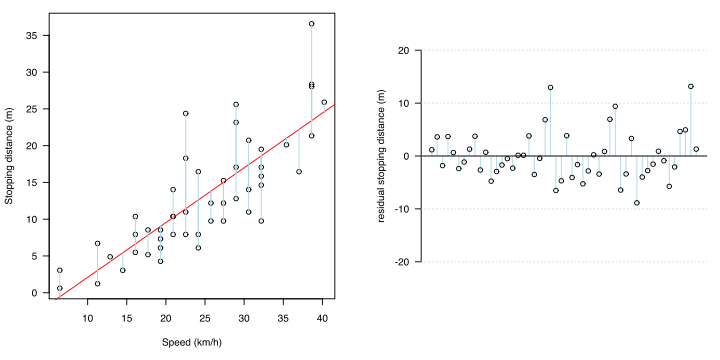
Statistisch gesehen ist dies die Zeit, in der die folgenden beiden nicht für den Fehler gelten (Residuum: Differenz zwischen dem gemessenen Wert und dem geschätzten Regressionswert).
・ Universalität
・ Homoskedastizität
Bei der Berechnung der Regressionsgleichung nach der Methode der kleinsten Quadrate sind Fehlerunvoreingenommenheit und Homoskedastizität als Voraussetzungen erforderlich.Fehlerunvoreingenommenheit bedeutet, dass der erwartete Wert des Fehlers bei jedem x 0 ist.Wenn im Fall einer Regressionslinie irgendwo in x gemittelt wird, bedeutet dies, dass der Fehler ohne Verzerrung auf dieser Linie liegt.
https://detail.chiebukuro.yahoo.co.jp/qa/question_detail/q1182674801
Homoskedastizität bedeutet, dass die Fehlervariation (Varianz) für jedes x gleich ist.
Wenn man diese überall in x zusammenfasst, bedeutet der Fehler, dass der Fehler um die Regressionslinie auf die gleiche Weise darüber und darunter variiert. Die Tatsache, dass es überall in x gleich ist, bedeutet, dass sich die Fehlerverteilung auch dann nicht ändert, wenn sich x ändert, das heißt, sie ist nicht korreliert.
Bestätigungsmethode
Diese sind im Restdiagramm und im QQ-Diagramm des Rückstands zu sehen.
Problemumgehung und Art der Skalenkonvertierung
Mit anderen Worten, wenn die Residuen analysiert werden und die obigen Voraussetzungen nicht erfüllt sind (wenn eine gewisse Tendenz für den Residuen besteht), kann das Regressionsmodell die Beziehung zwischen x und y durch mathematische Verarbeitung besser darstellen. Es wird berücksichtigt.Eine der Problemumgehungen besteht darin, die Zielvariable zu konvertieren.
Wenn beispielsweise die Zielvariable einen Wert hat, der exponentiell ansteigt, nimmt der Fehler zu, wenn der Vorhersagebereich größer wird.Um ein solches nichtlineares Modell als lineares Modell auszudrücken, setzen Sie die logarithmische Transformation (log) auf y.
Die wichtigste ist die logarithmische Transformation, aber es gibt noch andere
- √ (Wurzel-) Transformation
- Boxcox-Konvertierung
- Gegenseitige Umwandlung
Und so weiter.
Es gibt jedoch andere Problemumgehungen, z. B. das Erhöhen von Variablen, das Hinzufügen von Begriffen des Grades XNUMX oder höher und das Ändern der Bewertungsfunktion.
Die Zielvariable selbst muss nicht normal verteilt sein
Es sind die Residuen, die normal verteilt werden müssen.Es ist keine erklärende Variable oder eine objektive Variable.Versteh das nicht falsch.Der Grund, warum die Residuen normalverteilt werden müssen, besteht darin, dass sie dem Nenner der Teststatistik des F-Tests zur Varianzanalyse entsprechen. Dies liegt daran, dass die F-Verteilung auf der Prämisse basiert, dass sowohl der Nenner als auch der Zähler normal verteilt sind.
Müssen die erklärenden Variablen und objektiven Variablen der Regressionsanalyse nicht normal verteilt sein?
In Anbetracht der Bildung der Bewertungsfunktion der Regressionsanalyse funktioniert sie gut für Daten, die keiner Normalverteilung folgen, so dass es sich um eine Art plausibles Gefühl handelt.
Dies ist die Notwendigkeit einer numerischen Umrechnung in die Zielvariable.Wenn sich die Genauigkeit verbessert, sollte meiner Meinung nach letztendlich eine Skalenkonvertierung durchgeführt werden.