목적 변수를 스케일 변환할 필요성【기계 학습】
기계 학습이나 딥 러닝에서 특징량의 변환이 중요한 것은 잘 논의됩니다.예를 들면 다음의 서적 등.
반면에 목적 변수에 대한 정보는별로 없었습니다.그래서 회귀 태스크에서 목적 변수는 변환되어야 하는지를 조사한 결과를 정리해 둡니다.
목표 변수를 스케일 변환할 필요성
당연하지만, 어떤 경우에는 그 필요가 있습니다.
필요한 장면
통계적으로는, 오차(잔차:실측치와 회귀 추정치의 차이)에 대해서, 이하의 2개가 성립하지 않는 때라고 하는 것입니다.
・보편성
· 등 분산성
최소제곱법으로 회귀식을 구할 때, 전제조건으로서 오차의 불편성과 등분산성이 있습니다.오차의 불편성이란, 어떤 x에 있어서도, 오차의 기대치는 0이 된다고 하는 것입니다.회귀 직선의 경우 x의 어느 곳에서나 평균하면 오차가 치우치지 않고 그 직선에 있음을 의미합니다.
https://detail.chiebukuro.yahoo.co.jp/qa/question_detail/q1182674801
등분산성이란, 어떤 x에 있어서도, 오차의 불균형(분산)은 동일하다는 의미입니다.
이것들을 정리하면, x의 어느 곳에서도, 오차는 회귀 직선을 중심으로 해, 그 상하에 똑같이 편차하는 것을 의미합니다. x의 어느 곳에서나 동일하다는 것은 x가 변화해도 오차 분포는 그에 따라 변화하지 않는다, 즉 무상관임을 의미합니다.
확인 방법
이들은 잔류물 플롯(residual plot) 또는 잔류물의 QQ plot에서 확인할 수 있습니다.
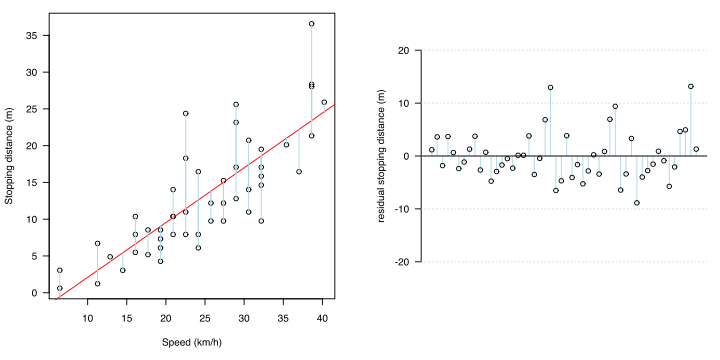
해결 방법 및 스케일 변환 유형
즉, 잔차를 분석하여 상술한 전제조건이 성립되지 않으면(잔사의 존재 방식에 어떠한 경향이 있다면), 그 회귀 모델은 수학적 처리에 의해 x와 y의 관계성을 보다 적절하게 표현할 수 있다. 라고 생각됩니다.그 대처법의 하나로서 목적 변수의 변환을 실시합니다.
예를 들어, 목적 변수에 지수 함수적으로 커지는 값을 가질 때 예측 영역이 큰 값측이 될수록 오차가 커집니다.이러한 비선형 모델을 선형 모델로 표현하기 위해 로그 변환(log)을 y로 합니다.
가장 중요한 것은 로그 변환이지만 다른 것
- √(루트) 변환
- Boxcox 변환
- 역수 변환
등이있는 것 같습니다.
다만 대처법은 그 밖에도 있어, 변수를 늘리거나, XNUMX차 이상의 항을 더하거나, 평가 함수를 변경하는 것도 생각할 수 있습니다.
목적변수 자체가 정규분포될 필요는 없다.
정규분포하고 있을 필요가 있는 것은 잔차이다.설명 변수나 목적 변수가 아니다.이것을 틀리지 말라.잔차가 정규 분포되어 있어야 하는 이유는 분산 분석의 F 검정의 검정 통계량의 분모에 해당하기 때문이다. F분포는 분모·분자 모두 정규분포하고 있는 것이 전제이기 때문이다.
회귀분석의 설명변수나 목적변수는 정규분포되어 있지 않아도 되는가?
회귀 분석의 평가 함수의 성립을 생각하면, 정규 분포에 따르지 않는 데이터에 대해서도 맞도록(듯이) 일하기 때문에, 어떤 종류 가장 좋은 느낌입니다.
이상, 목적 변수에 있어서의 수치 변환의 필요성이었습니다.궁극적으로는 정밀도가 오르면 스케일 변환하면 좋다고 생각합니다.