Noodzaak van schaalconversie van objectieve variabele [machine learning]
Vaak wordt beweerd dat feature-conversie belangrijk is bij machine learning en deep learning.Bijvoorbeeld de volgende boeken.
Aan de andere kant was er niet veel informatie over de objectieve variabele.Daarom zal ik het resultaat van het onderzoek of de objectieve variabele in de regressietaak moet worden geconverteerd, samenvatten.
Noodzaak om de objectieve variabele te schalen
In sommige gevallen is er natuurlijk behoefte aan.
Noodzakelijke scène
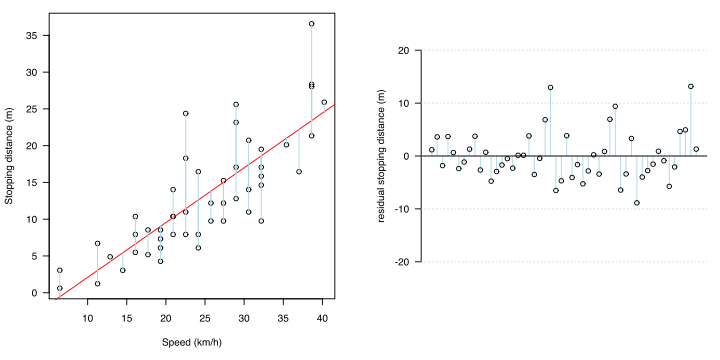
Statistisch gezien is het het tijdstip waarop de volgende twee niet gelden voor de fout (residu: verschil tussen de gemeten waarde en de geschatte regressiewaarde).
・ Universaliteit
・ Homoscedasticiteit
Bij het berekenen van de regressievergelijking met de kleinste-kwadratenmethode, zijn er foutonafhankelijkheid en homoscedasticiteit als voorwaarden.Fout-onbevooroordeeldheid betekent dat de verwachte waarde van de fout 0 is bij elke x.In het geval van een regressielijn, als ergens in x gemiddeld wordt, betekent dit dat de fout zich op die regel bevindt zonder enige vertekening.
https://detail.chiebukuro.yahoo.co.jp/qa/question_detail/q1182674801
Homoscedasticiteit betekent dat de foutvariatie (variantie) gelijk is voor elke x.
Als je deze overal in x samenvoegt, betekent de fout dat de fout rond de regressielijn varieert op dezelfde manier erboven en eronder. Het feit dat het overal in x hetzelfde is, betekent dat zelfs als x verandert, de foutverdeling er niet mee verandert, dat wil zeggen dat het niet gecorreleerd is.
Bevestigingsmethode
Deze zijn te zien in de residuale plot en de QQ-plot van het residu.
Tijdelijke oplossing en type weegschaalconversie
Met andere woorden, als de residuen worden geanalyseerd en aan de bovenstaande voorwaarden niet wordt voldaan (als er een neiging is om het residu te zijn), kan het regressiemodel de relatie tussen x en y beter weergeven door wiskundige verwerking.Een van de oplossingen is om de objectieve variabele om te zetten.
Als de objectieve variabele bijvoorbeeld een waarde heeft die exponentieel toeneemt, neemt de fout toe naarmate het voorspellingsbereik groter wordt.Om een dergelijk niet-lineair model als een lineair model uit te drukken, stelt u de logaritmische transformatie (log) in op y.
De belangrijkste is logaritmische transformatie, maar er zijn er nog meer
- √ (root) transformatie
- Boxcox conversie
- Wederzijdse conversie
Enzovoorts.
Er zijn echter andere oplossingen, zoals het verhogen van variabelen, het toevoegen van termen van graad XNUMX of hoger en het wijzigen van de evaluatiefunctie.
De objectieve variabele zelf hoeft niet normaal verdeeld te zijn
Het zijn de residuen die normaal verdeeld moeten worden.Het is geen verklarende variabele of een objectieve variabele.Begrijp dit niet verkeerd.De reden waarom de residuen normaal verdeeld moeten worden, is dat ze overeenkomen met de noemer van de teststatistiek van de F-toets voor variantieanalyse. Dit komt omdat de F-verdeling is gebaseerd op de premisse dat zowel de noemer als de teller normaal verdeeld zijn.
Moeten de verklarende variabelen en objectieve variabelen van regressieanalyse niet normaal verdeeld zijn?
Gezien de vorming van de evaluatiefunctie van regressieanalyse, werkt het goed voor gegevens die geen normale verdeling volgen, dus het is een soort aannemelijk gevoel.
Dit is de noodzaak van numerieke conversie in de objectieve variabele.Uiteindelijk, als de nauwkeurigheid verbetert, vind ik dat schaalconversie moet worden uitgevoerd.