Необходимость масштабного преобразования целевой переменной [Машинное обучение]
Часто утверждают, что преобразование функций важно в машинном обучении и глубоком обучении.Например, следующие книги.
С другой стороны, информации об объективной переменной было немного.Поэтому я обобщу результат исследования, следует ли преобразовывать объективную переменную в задаче регрессии.
Необходимо масштабировать объективную переменную
Конечно, в некоторых случаях есть необходимость.
Необходимая сцена
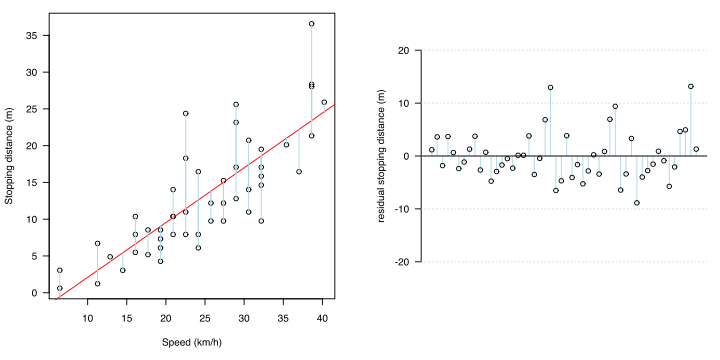
Статистически это время, когда следующие два не подходят для ошибки (остаток: разница между измеренным значением и оценочным значением регрессии).
・ Универсальность
・ Гомоскедастичность
При вычислении уравнения регрессии методом наименьших квадратов предпосылками являются объективность ошибок и гомоскедастичность.Несмещенность ошибки означает, что ожидаемое значение ошибки равно 0 при любом x.В случае линии регрессии, если она усредняется где-либо в x, это означает, что ошибка находится на этой линии без какого-либо смещения.
https://detail.chiebukuro.yahoo.co.jp/qa/question_detail/q1182674801
Гомоскедастичность означает, что вариация (дисперсия) ошибки одинакова для любого x.
Собирая их вместе, везде в x, ошибка означает, что ошибка изменяется вокруг линии регрессии одинаково выше и ниже нее. Тот факт, что оно везде одинаково в x, означает, что даже если x изменяется, распределение ошибок не изменяется вместе с ним, то есть оно некоррелировано.
Метод подтверждения
Их можно увидеть на графике остатка и графике QQ остатка.
Обходной путь и тип преобразования шкалы
Другими словами, если остатки анализируются и указанные выше предварительные условия не выполняются (если существует некоторая тенденция к появлению остатка), регрессионная модель может лучше представить взаимосвязь между x и y с помощью математической обработки.Один из обходных путей - преобразовать целевую переменную.
Например, когда целевая переменная имеет значение, которое экспоненциально увеличивается, ошибка увеличивается по мере увеличения диапазона прогноза.Чтобы выразить такую нелинейную модель как линейную модель, установите логарифмическое преобразование (log) на y.
Самый главный из них - логарифмическое преобразование, но есть и другие.
- √ (корень) преобразование
- Преобразование Boxcox
- Взаимное преобразование
И так далее.
Однако есть и другие обходные пути, такие как увеличение переменных, добавление членов степени XNUMX или выше и изменение функции оценки.
Сама целевая переменная не обязательно должна иметь нормальное распределение.
Это остатки, которые необходимо распределить нормально.Это не объясняющая переменная или объективная переменная.Не поймите неправильно.Причина, по которой остатки должны быть нормально распределены, заключается в том, что они соответствуют знаменателю тестовой статистики F-теста для дисперсионного анализа. Это связано с тем, что F-распределение основано на предположении, что и знаменатель, и числитель распределены нормально.
Разве объясняющие переменные и объективные переменные регрессионного анализа не обязательно должны иметь нормальное распределение?
Учитывая формирование оценочной функции регрессионного анализа, он хорошо работает для данных, которые не подчиняются нормальному распределению, так что это своего рода правдоподобное ощущение.
Это необходимость числового преобразования в целевой переменной.В конечном итоге, если точность улучшится, я считаю, что преобразование масштаба должно быть выполнено.