Necesidad de conversión de escala de la variable objetiva [aprendizaje automático]
A menudo se argumenta que la conversión de características es importante en el aprendizaje automático y el aprendizaje profundo.Por ejemplo, los siguientes libros.
Por otro lado, no hubo mucha información sobre la variable objetivo.Por lo tanto, resumiré el resultado de investigar si la variable objetivo debe convertirse en la tarea de regresión.
Necesita escalar la variable objetivo
Por supuesto, existe la necesidad en algunos casos.
Escena necesaria
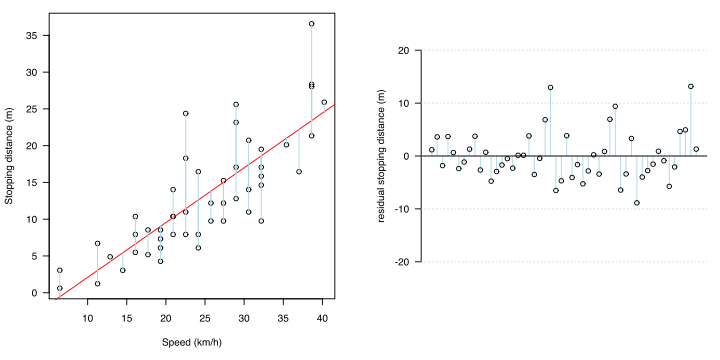
Estadísticamente, es el momento en que los dos siguientes no son válidos para el error (residual: diferencia entre el valor medido y el valor estimado de regresión).
・ Universalidad
・ Homoscedasticidad
Cuando se calcula la ecuación de regresión por el método de mínimos cuadrados, existen como requisitos previos la falta de sesgo del error y la homocedasticidad.El sesgo del error significa que el valor esperado del error es 0 en cualquier x.En el caso de una línea de regresión, si se promedia en cualquier lugar de x, significa que el error está en esa línea sin ningún sesgo.
https://detail.chiebukuro.yahoo.co.jp/qa/question_detail/q1182674801
Homoscedasticidad significa que la variación del error (varianza) es igual para cualquier x.
Poniendo estos juntos, en todas partes en x, el error significa que el error varía alrededor de la línea de regresión de la misma manera por encima y por debajo de ella. El hecho de que sea el mismo en todas partes en x significa que incluso si x cambia, la distribución de errores no cambia con él, es decir, no está correlacionado.
Método de confirmación
Estos se pueden ver en el gráfico de residuos y el gráfico QQ del residuo.
Solución alternativa y tipo de conversión de escala
En otras palabras, si se analizan los residuos y no se cumplen las condiciones previas anteriores (si existe alguna tendencia a que lo sea el residuo), el modelo de regresión puede representar mejor la relación entre xey mediante procesamiento matemático.Una de las soluciones es convertir la variable objetivo.
Por ejemplo, cuando la variable objetivo tiene un valor que aumenta exponencialmente, el error aumenta a medida que aumenta el rango de predicción.Para expresar un modelo no lineal como un modelo lineal, establezca la transformación logarítmica (log) en y.
La más importante es la transformación logarítmica, pero hay otras
- √ (raíz) transformación
- Conversión de Boxcox
- Conversión recíproca
Y así.
Sin embargo, existen otras soluciones, como aumentar las variables, agregar términos de grado XNUMX o superior y cambiar la función de evaluación.
La variable objetivo en sí no tiene que estar distribuida normalmente
Son los residuos los que deben distribuirse normalmente.No es una variable explicativa ni una variable objetiva.No lo malinterpretes.La razón por la que los residuos deben distribuirse normalmente es que corresponden al denominador del estadístico de prueba de la prueba F para el análisis de varianza. Esto se debe a que la distribución F se basa en la premisa de que tanto el denominador como el numerador están distribuidos normalmente.
¿No es necesario que las variables explicativas y las variables objetivas del análisis de regresión se distribuyan normalmente?
Teniendo en cuenta la formación de la función de evaluación del análisis de regresión, funciona bien para datos que no siguen una distribución normal, por lo que es una especie de sentimiento plausible.
Lo anterior es la necesidad de conversión numérica en la variable objetivo.En última instancia, si mejora la precisión, creo que debería realizarse una conversión de escala.