Necessity of scale conversion of objective variable [Machine learning]
It is often argued that feature conversion is important in machine learning and deep learning.For example, the following books.
On the other hand, there was not much information about the objective variable.Therefore, I will summarize the result of investigating whether the objective variable should be converted in the regression task.
Need to scale the objective variable
Of course, there is a need in some cases.
Necessary scene
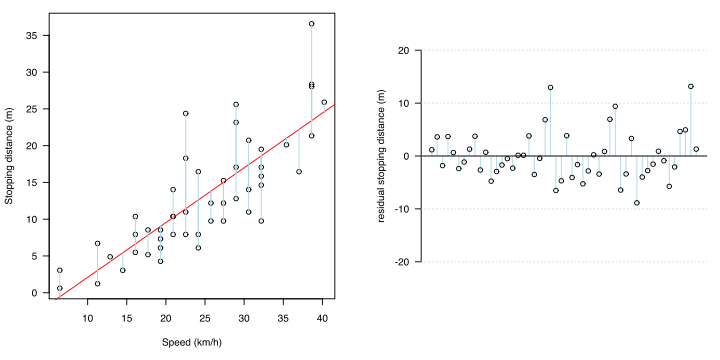
Statistically, it is the time when the following two do not hold for the error (residual: difference between the measured value and the regression estimated value).
・ Universality
・ Homoscedasticity
When calculating the regression equation by the least squares method, there are error unbiasedness and homoscedasticity as prerequisites.Error unbiasedness means that the expected value of the error is 0 at any x.In the case of a regression line, if averaged anywhere in x, it means that the error is on that line without any bias.
https://detail.chiebukuro.yahoo.co.jp/qa/question_detail/q1182674801
Homoscedasticity means that the error variation (variance) is equal for any x.
Putting these together, everywhere in x, the error means that the error will vary above and below the regression line in the same way. The fact that it is the same everywhere in x means that even if x changes, the error distribution does not change with it, that is, it is uncorrelated.
Confirmation method
These can be seen in the residual plot and the QQ plot of the residue.
Workaround and type of scale conversion
In other words, if the residuals are analyzed and the above preconditions are not met (if there is some tendency for the residue to be), the regression model can better represent the relationship between x and y by mathematical processing. It is considered.One of the workarounds is to convert the objective variable.
For example, when the objective variable has a value that increases exponentially, the error increases as the prediction range becomes larger.Set the log transformation (log) to y in order to represent such a nonlinear model as a linear model.
The most major one is logarithmic transformation, but there are others
- √ (root) transformation
- Boxcox conversion
- Reciprocal conversion
And so on.
However, there are other workarounds, such as increasing variables, adding terms of degree XNUMX or higher, and changing the evaluation function.
The objective variable itself does not have to be normally distributed
It is the residuals that need to be normally distributed.It is not an explanatory variable or an objective variable.Don't get this wrong.The reason why the residuals need to be normally distributed is that they correspond to the denominator of the test statistic of the F-test for analysis of variance. This is because the F distribution is based on the premise that both the denominator and the numerator are normally distributed.
Do the explanatory variables and objective variables of regression analysis need not be normally distributed?
Considering the formation of the evaluation function of regression analysis, it works well for data that does not follow a normal distribution, so it is a kind of plausible feeling.
This is the necessity of numerical conversion in the objective variable.Ultimately, if the accuracy improves, I feel that scale conversion should be done.